QUIC протокол
Щастливи сме да обявим, че сме първият български хостинг доставчик, който предлага QUIC (Quick UDP Internet Connection) за нашите клиенти. След проведени тестове през лятото, вече е включен и наличен от началото на октомври. Протоколът е създаден да наследи и надгради HTTP/2 като подобри няколко негови недостатъка, които всъщност са непоправими. Накратко QUIC е TLS+HTTP/2 върху UDP, като не се използва никъде TCP като транспортен протокол, а е заменен с UDP.
Сега ще ви покажем няколко недостатъка на TCP, които са непоправими в текущите условия.
1. TCP страда от бавен старт (TCP slow start). Когато се създаде нова TCP връзка, сървърът не знае каква е честотната лента на клиента. Поради това той започва бавно да увеличава броя на изпращаните едновременно пакети, като започва от 3. Ако клиента отговори, че е получил и трите пакета, сървъра увеличава броя на изпратените едновременно пакети на 6. Когато и на 6-те се отговори, се увеличават на 12, после на 21 и т.н.
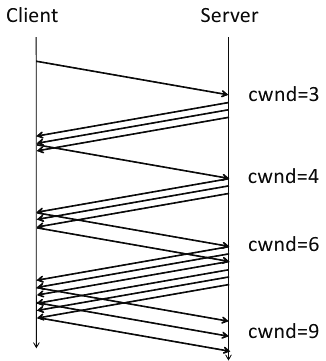
Така с поетапното увеличаване на броя на пакетите, сървъра се нагажда към запълване на целия честотен канал към клиента, докато връзката е активна, като се старае да не претовари канала. Ето и как експоненциално с броя на едновременно изпратените пакети се увеличава и броят на изпратените данни. Колкото по-дълго се държи връзката отворена, толкова повече данни се изпращат едновременно.
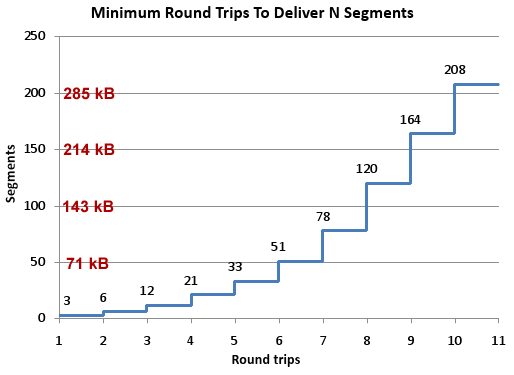
Това обаче е било валидно преди 43 години когато TCP (RFC 674 и RFC 793) е бил проектиран и имплементиран за пръв път. Тогава комуникациите са били изграждани по модеми между различните компютри и съвременните мегабити (или гигабити) са били в сферата на научната фантастика. За съжаление, точно това е една от причините, поради които преминаването в днешно време от 5 Mbps към 10 Mbps води до увеличение на скоростта на сайтовете с едва 5%.
За наше щастие има редица компании, активно работещи за увеличаването на initcwnd от 3 на 10 (RFC 6928). Има и такива, при които е 30 (MaxCDN), както и такива при които е 70 (Cachefly), но това, разбира се, са предимно кеширащи сървъри. Има и един много неприятен момент, а именно - безразборното увеличаване на изпратените пакети не означава, че броят на получените пакети от клиента също се увеличава. Всъщност това е един друг параметър (RWIN), който в различните операционни системи има различни стойности за различните мрежи. Примерно Windows 9X/NT има 8192 байта прозорец. При XP e между 8192, ако скоростта на трасето е под 1 Mbps; 16384, ако е между 1 и 100 Mbps и 65535, ако е над 10 Mbps. От Vista и следващите, стойността е 65535 или повече. Linux 2.6 буфера е 5840 (3*MSS, докато от 3.0 нагоре е 14600 (10*MSS).
Всъщност това е една от причините, поради които HTTP/2 е много по-бърз от HTTP 1.1. Реално той ползва само една връзка към сървъра за обмен на данни и я държи отворена, докато всичките заявки към съвъра не се обработят. Така по-дълго отворената връзка увеличава експоненциално броя на предадените данни за единица време. Но всичко зависи и от двата параметъра initcwnd и RWIN при клиента и при сървъра, а те не може да се модифицират без промени в самите операционни системи.
2. TCP има и още един много съществен момент - когато се изгубва пакет се стартира сложна и времеемка организация за изпращането наново на този пакет.
В идеалния случай, ако изпратим пакетите ето така 1-2-3-4-5-6, те се получават в същия ред и при клиента 1-2-3-4-5-6. Но понякога пакет се изгубва и клиента получава нещо като 1-2-3-5-6 (липсва пакет Н:4), това е по-известно като out-of-order. В този случай IP стека въпреки, че разполага с пакет 5 и 6 не ги предава по-нагоре към самото приложение, защото липсва пакет Н:4 и той изпраща към сървъра команда за изпращането само на пакет Н:4 наново. По някое време пакет Н:4 се изпраща от сървъра и се получава при клиента. Тогава всички получени пакети (4, 5 ,6) се изпращат към самото приложение. Този протокол се казва TCP congestion protocol (RFC 2581).
Има два интересни момента, когато се случи изпращане на липсващ пакет. Първият момент е, че се блокира обработката на последващите пакети. Ако при HTTP 1 е важен реда на пакетите, то във мултиплексорния HTTP/2 това не е така. В последният, на една TCP връзка се предават едновременно няколко различни потока и загубата на пакет води до временно блокиране на обработката на всички потоци. Примерно, ако едновременно се предават 10 Mb видео файл, 1 Mb снимка и 10 Kb CSS файл и ето така - 1-видео 2-снимка 3-CSS по следния ред 1.1-1.2-1.3,2.1-2.2-2.3,3.1-3.2-3.3,4.1-4.2-4.3 (пакет.поток). Ако изгубим пакет 3.3, то се спира обработката на 4.1-4.2-4.3, което блокира зареждането на снимката и на видео файла, въпреки че те са независими от обработката на CSS файла.

Вторият интересен момент е, че след изпращане на липсващ пакет винаги има някаква форма на намаляване на броя на изпратените пакети от сървъра. А как - зависи от алгоритмите, които сървъра използва. Оригиналният алгоритъм се казва Tahoe, при което броят на изпратените пакети започва да се брои от 1, което си е все едно TCP slow start, но по средата на връзката. Подобреният алгоритъм се казва Reno, при което броят на пакетите след ретрансмисия на изгубен се прави да е /2 на текущото, т.е. ако изпращаме 20 пакета едновременно след изпращането на изгубения се изпращат 10.
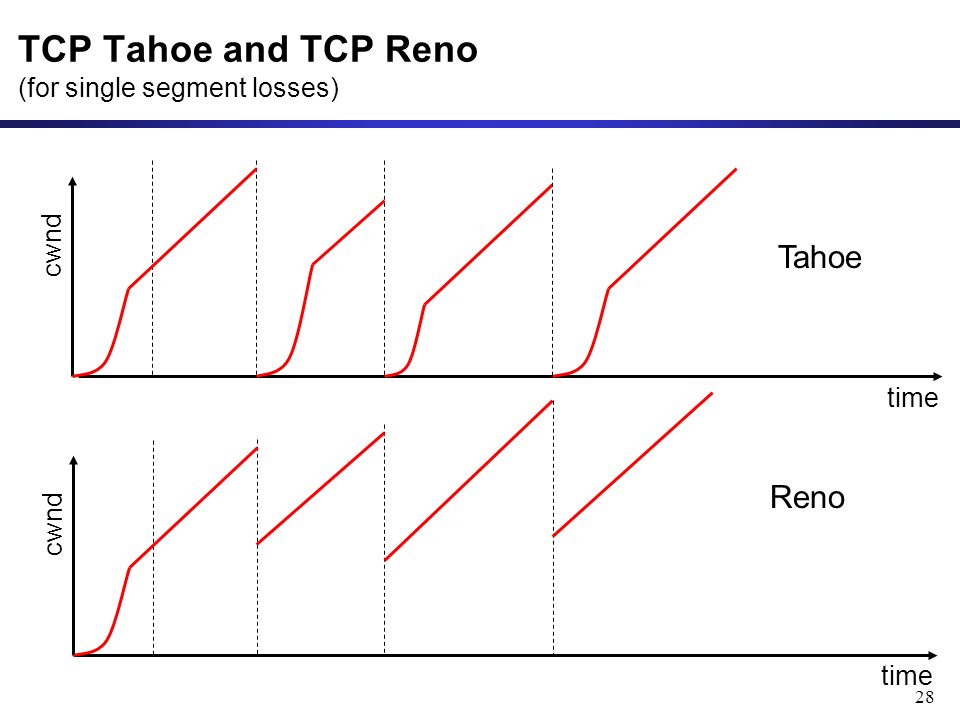
Тук за съжаление страдат както HTTP 1.1, така и HTTP/2. Както по-горе написахме - това зависи изцяло от обработката на IP стека в различните операционни системи и механизмите не може да се модифицират без промени в самите операционни системи. В съвременните системи се използват други алгоритми - най-често това е TCP BIT или TCP CUBIC, но там също има елементи на намаляване на честотната лента при загуба на пакет и повторното му изпращане.
3. Поредният по-значим проблем е най-често видим в мобилните мрежи - когато в движение мрежата ни смени адреса с нов IP адрес. Например, в момента нашият адрес е 1.2.3.4 и ние се свързваме със сървъра, движим се и излизаме от обхвата на едната клетка и влизаме в другата. Другата клетка ни зачислява адрес 2.3.4.5. В този случай, обаче, се получава малка катастрофа в IP стека. Тъй като имаме нов IP адрес, съществуващата връзка със сървъра от IP 1.2.3.4 се прекъсва и се създава чисто нова от адрес 2.3.4.5, като се изискват само данните, които не са получени от предната връзка. В този случай TCP започва всичките инициализации отначало, като чисто нова връзка. Това разбира се води до деградиране на производителността (TCP slow start) и води до натоварване на сървъра (TCP blackhole detection), защото той държи едновременно две връзки към 2 клиента - 1.2.3.4 и 2.3.4.5.
В общия случай, това най-често се случва на мобилните GSM потребители, но подобни проблеми има и при по-сложни WiFi мрежи, когато потребителят се движи между различните точки на мрежата.
При това положение няма какво да се направи, защото връзката между клиента и сървъра се идентифицира по IP адрес и IP порт на клиента. При получаването на друг IP адрес връзката със сървъра се разпада по съществуващия адрес и се изгражда нова връзка през новия адрес.
4. И последно, винаги когато се създава връзка се прави първо TCP ръкостискане, едва след това може да се изпратят данните. Ако се създава сигурна връзка, в горните стъпки се добавя и TLS ръкостискане.
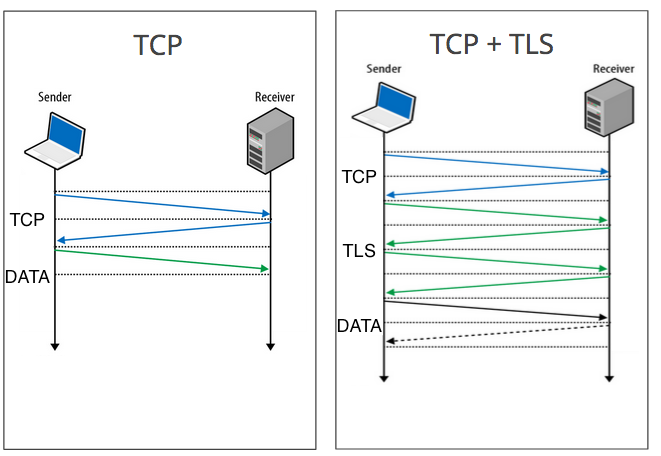
Което разбира се няма как да се избегне. А друг недостатък е, че ако се създава за втори път връзка в къс период от време към същия сървър, целият механизъм трябва да се повтори наново.
Като се оценят всички тези недостатъци ясно се вижда, че понякога е възможно HTTP/2 всъщност да се представя много по-зле от HTTP 1.1. И от това страдат най-вече мобилните потребители, както и тези, използващи връзки със загуби по трасето. Разбира се, има предложения за отстраняването на всички горепосочени недостатъци, но това ще доведе до срив на интернет. Защото отстраняването ще принуди всички използващи интернет да обновят едновременно своите мрежови оборудвания, за да използват новия интернет. По този начин се получава класически “Параграф 22”.
За тази цел Google разработиха QUIC и парадоксалното е, че всъщност той не използва надежния TCP като транспортен протокол, а използва ненадежния UDP като такъв.
Каква е разликата между TCP и UDP?
Ако първият създава връзка между 2 хоста в интернет и гарантира (до колкото е възможно това, разбира се), че информацията ще бъде предадена правилно и в същия ред, то втория не гарантира нищо такова. При UDP не се създава връзка (connectionless) и просто се предават данни (datagrams) между 2 хоста. Не се гарантира, че данните ще пристигнат в другия хост, както и не се гарантира в каква подредба ще пристигнат. На практика, ако сте използвали VoIP или някоя компютърна игра, сте установили, че почти всички използват UDP за трансфер на данни. Въпреки липсата на всякакви гаранции, такива приложения създават протокол на по-високо ниво върху UDP, където се обменят данни между 2 хоста. Ако се стигне до моментен срив във VoIP, това води до роботизиране на гласовете или тишина в разговора. При игрите най-често се проявява като лаг или ако е продължително - до изхвърляне от сървъра поради разсинхронизиране. Друг популярен пример за масово използване на UDP е и DNS системата.
Изхождайки от досегашния си опит и примерите по-горе, Google прецениха, че при трасета със загуба на данни е по-добре да се използва UDP като транспортен протокол, вместо TCP.
Предимства на QUIC (TLS+HTTP/2 върху UDP) пред HTTP/2 (TLS+HTTP/2 върху TCP).
1. QUIC не страда от TCP slow start, поради разработен чисто нов механизъм за създаване на връзка. Както и друг механизъм за повторно свързване към сървър в близък период от време.
2. QUIC използва други механизми за повторно изпращане на пакети, технологично по-добри от тези на TCP.
3. QUIC може да сменя в движение адреса на един от двата хоста участващи във връзката. Може и да се смени и порта в движение. В QUIC се използва Connection ID за еднозначно идентифициране на псевдо-връзката. Отделно вътре самите потоци се идентифицират със Stream ID подобно на HTTP/2. QUIC може да използва управление на потока за подаване на данни (flow control) както на ниво поток, така и на ниво връзка.
4. QUIC използва по-добра сигнализация на ниво връзка, отколкото TCP. Ако TCP използва само ACK и SACK като потвърждение какво е получено като пакети, то QUIC използва само NACK, което указва единствено какво е изгубено и трябва да бъде препратено наново.
5. QUIC използва система за контрол на грешките, при която е възможно да се възстанови изгубен пакет в дадена група на база на предходните и следващите пакети в нея, без да се изпраща от отсрещната страна наново.
6. QUIC криптира и аутентицира всичко, включително и хедърите на пакетите. Ако в TLS може да се видят TCP хедърите, защото само съдържанието е криптирано, то тук в QUIC само по време на първоначалното създаване на връзката може да се видят некриптирани хедъри. След това всичко се криптира и аутентицира. Това позволява да се избегнат и атаките с подправени IP хедъри (IP spoofing).
И малко тестове:
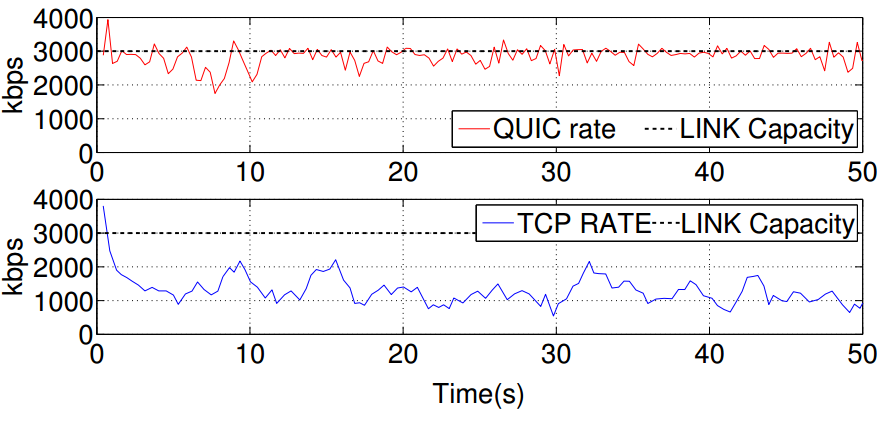
След всички тези благи вести, идва ред и на тъжните новини:
1. QUIC на този етап се поддържа само и единственно от Chrome.
2. От QUIC може да се възползват само и единственно сайтове, използващи сигурна връзка (HTTPS), което е още една причина да мигрирате към такава.
3. QUIC е все още експериментален протокол и са възможни много негови промени във времето. Все още не е стандартизиран от IETF (законодателя във Интернет протоколите) и е в процес на обсъждане и приемането му.
Как да познаете дали сайта ви вече използва QUIC?
С помощта на разширението на Chome или с използването на секретния линк chrome://net-internals/#quic, където може да се види статуса на връзките. 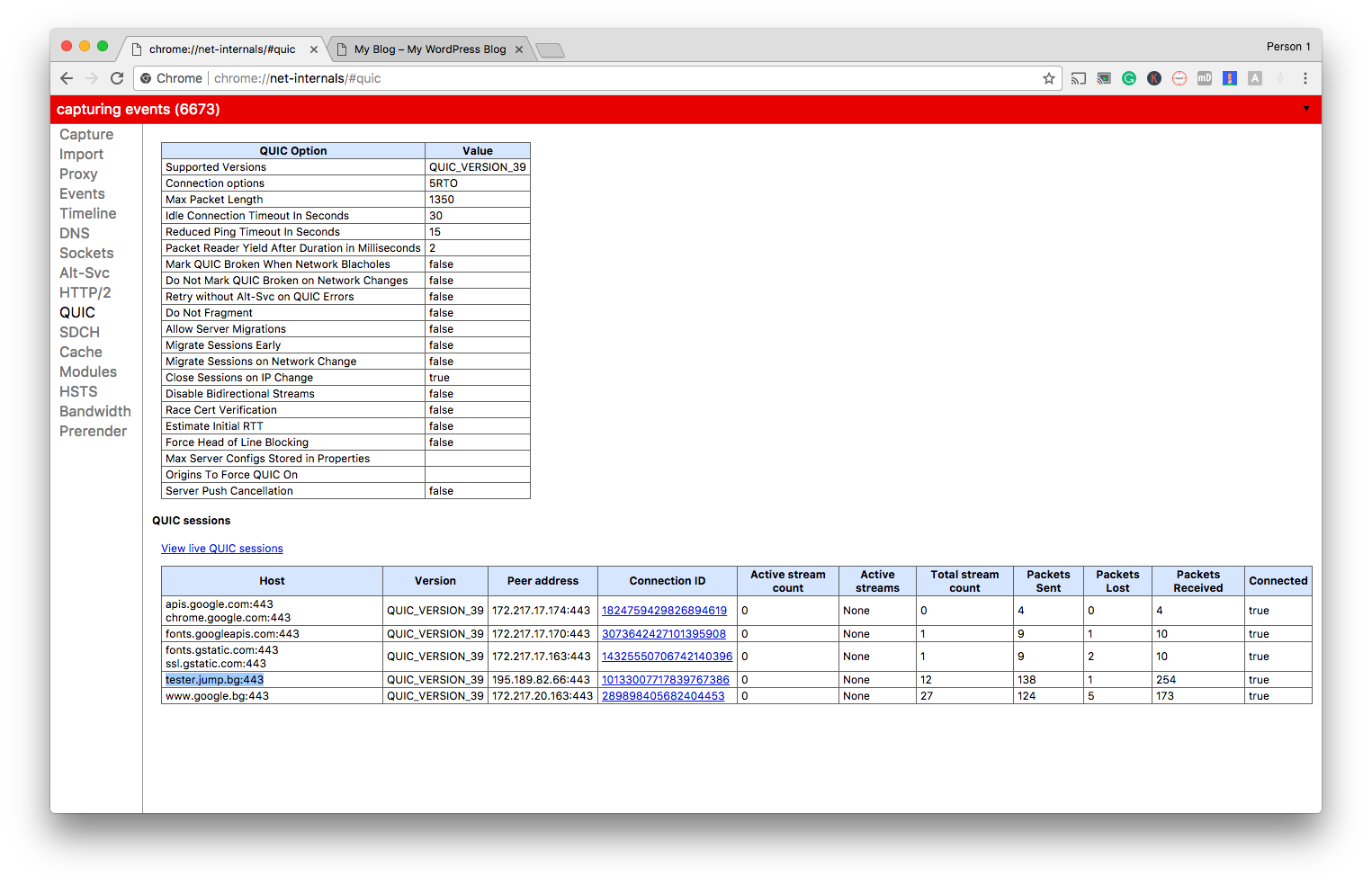
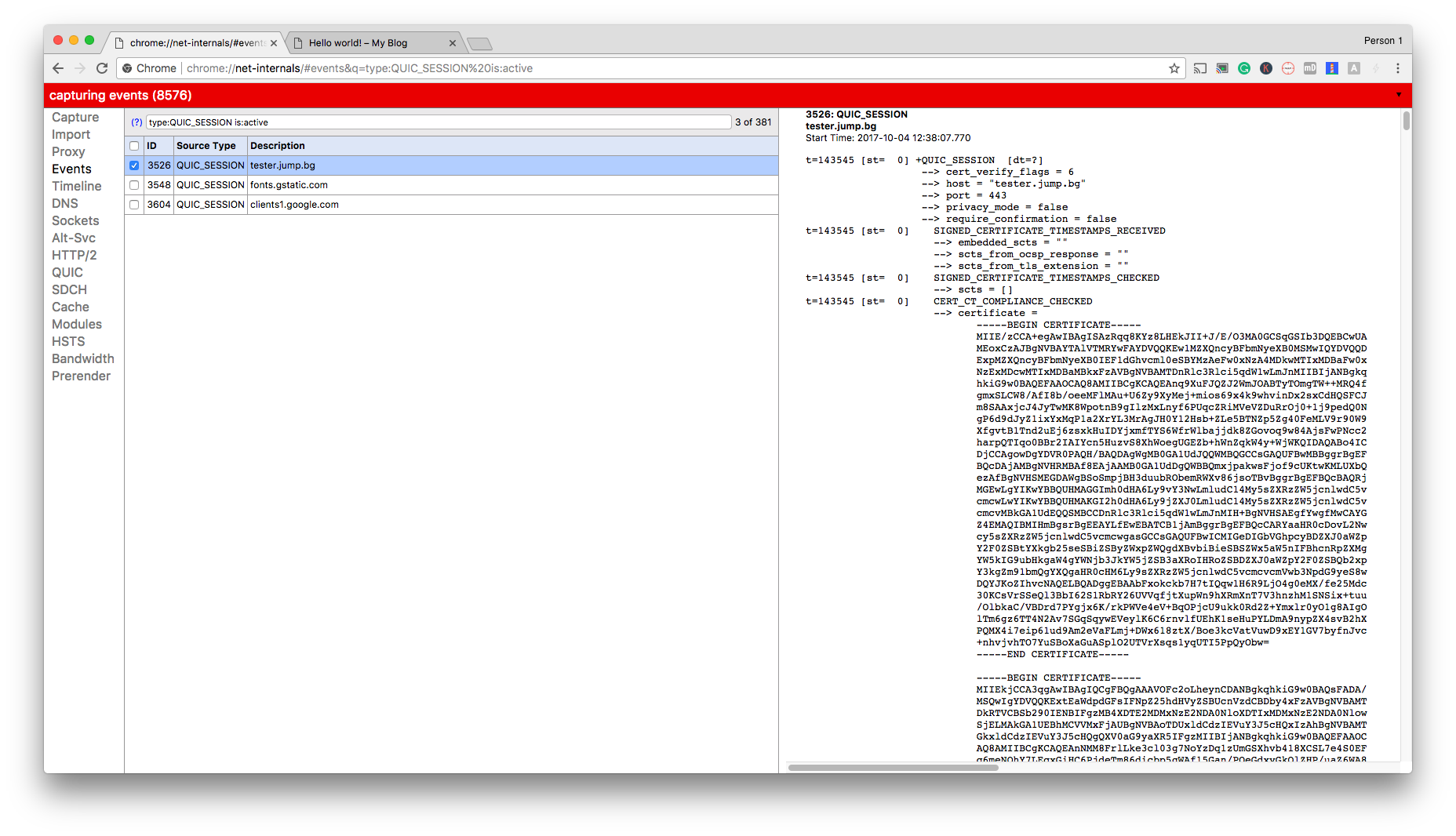
Ако желаете да експериментирате с QUIC, то можете да го използвате на нашия тестов сървър или да използвате други сайтове на нашия хостинг, които са със сигурна връзка. Можете да оставите вашите въпроси и мнения тук в коментарите, или в социалните мрежи.

